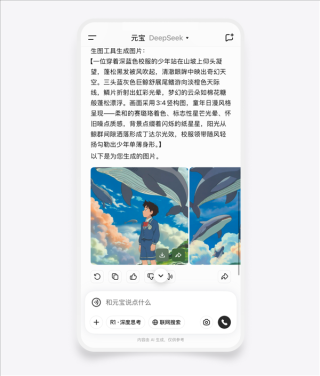
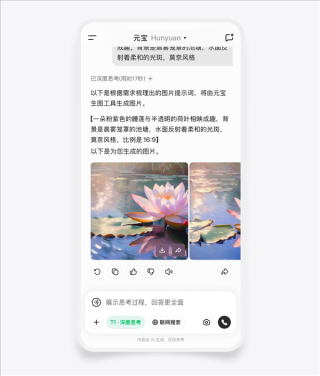
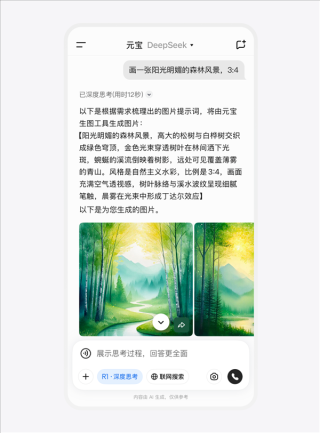
腾讯推出全新的混元视频生成工具并开源,该工具具备高精度的人物识别和物体定位能力,确保在视频处理过程中不会出现人物“变脸”和物体“漂移”的问题,这一创新工具将提高视频编辑的效率和准确性,为视频制作带来全新的体验。
腾讯混元今天正式推出并开源全新的多模态定制化视频生成工具——HunyuanCustom,该工具基于混元视频生成大模型(HunyuanVideo)打造,主体一致性效果超越现有的开源方案。
HunyuanCustom融合了文本、图像、音频、视频等多模态输入,具备高度控制力和生成质量的智能视频创作能力,它能够实现单主体视频生成、多主体视频生成、单主体视频配音、视频局部编辑等功能,生成的视频与用户输入的参考主体能够保持高度一致。
在部分场景下,创作者希望保持人物一致的情况下,改变人物所在的环境和动作,此前的视频生成模型都无法满足这一需求,而HunyuanCustom通过引入身份增强机制和多模态融合模块,真正实现了“图像提供身份,文本定义一切”。

HunyuanCustom广泛应用于视频创作者、短视频博主、电商从业者、广告创意人等不同用户和场景,在广告场景中,可以快捷变换商品背景、模特可以快速换衣服;在电商和客服场景中,可以快速低成本制作出生动的数字人商品介绍视频,或者制作特定穿着的数字人客服视频;在影视场景中,则可以快速制作短剧和小故事短视频。
HunyuanCustom具备业内领先的主体一致性建模能力,在单人、非人物体、多主体交互等多种场景,都能保持身份特征在视频全程的一致性与连贯性,人物不会“变脸”,物体不会“漂移”。

单主体生成能力已经开源并在混元官网上线,用户只需上传一张目标人物或物体的图片,并提供一句简单的文本描述,HunyuanCustom就能在完全不同的动作、服饰与场景中生成连贯自然的视频内容,目前多主体视频的生成功能也已开放体验,用户提供一张人物和一张物体的照片,并输入文字描述,即可能让这两个主体按要求出现在视频里。
HunyuanCustom不止于图像和文本的配合,还具备强大的扩展能力,在音频驱动模式下,用户可以上传人物图像并配上音频语音,模型便可生成人物在任意场景中说话、唱歌或进行其他音视频同步表演的效果,而在视频驱动模式下,HunyuanCustom支持将图片中的人物或物体自然地替换或插入到任意视频片段中,进行创意植入或场景扩展,轻松实现视频重构与内容增强。

HunyuanCustom的推出将为视频创作领域带来全新的体验,满足广大用户和场景的需求。